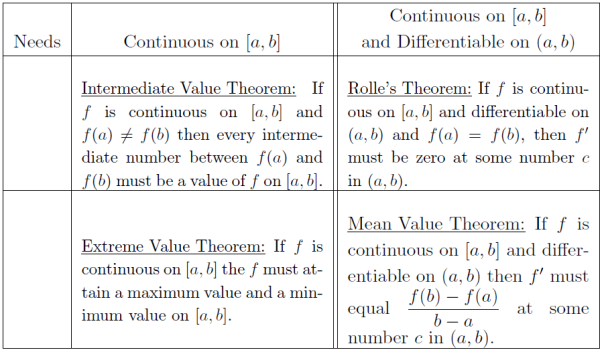


 at some
at some  and the average rate of change
and the average rate of change  with the intersection of the curve with the dashed line. Leading the class, I talked through the picture emphasizing that the average rate of change computes the slope of the dashed line, while
with the intersection of the curve with the dashed line. Leading the class, I talked through the picture emphasizing that the average rate of change computes the slope of the dashed line, while  different from the origin O. The perpendicular bisector to OP intersects the
different from the origin O. The perpendicular bisector to OP intersects the  -axis at a point Q. Do the positions of the points Q have a limit as P approaches the origin?
-axis at a point Q. Do the positions of the points Q have a limit as P approaches the origin?
 -coordinate of P, then taking the limit as
-coordinate of P, then taking the limit as  . But what I wanted the students to do was to do the geometric experiment of constructing the points Q for a family of points P along the parabola and looking to see if their locations showed a trend (just as we had done with numerical tables for limits of functions before).
. But what I wanted the students to do was to do the geometric experiment of constructing the points Q for a family of points P along the parabola and looking to see if their locations showed a trend (just as we had done with numerical tables for limits of functions before). sheet of paper, you can fold up the resulting tabs and join neighboring edges with tape to form a box.
sheet of paper, you can fold up the resulting tabs and join neighboring edges with tape to form a box.




This quarter I’m teaching “Foundations of Geometry,” a senior level course aimed primarily at future secondary mathematics teachers. It’s unlike any other course I’ve taught before because it has a bit of a split personality:
- one part history: examining the critiques of Euclid’s Elements and the attempts to eliminate the parallel postulate.
- one part a course in logic: discussing axiomatic systems and their properties and Hilbert’s triumphant axiomatization of geometry bringing it in line with set theory and analysis.
- one part a course in hyperbolic geometry.
We also have a course specifically on Euclidean geometry that many of these students also take, which is why the mathematical focus is on noneuclidean geometry. The course design is a learning experience for me because, although my mathematical expertise is in geometry, that expertise is in the subject geometry blossomed into during the 20th century after Hilbert’s revolution. By bringing the foundations of the subject in line with analysis, he brought Calculus to bear on the study of geometry allowing differential and algebraic geometry, together with Klein’s Erlangen program, to subsume the classical subject. While I know quite a bit about hyperbolic space, it is from this modern viewpoint rather than the axiomatic viewpoint of Lobachevsky. Tentatively, I plan to close the course by connecting the old with the new, but this might be a quixotic dream. We’ll see.
For quite some time while preparing this course, I struggled with how to begin on the first day. I finally decided that the best hook was to begin by analyzing the most famous proposition of euclidean geometry: The Pythagorean Theorem (PT).  There is a marvelous java applet by Jim Morey which animates Euclid’s proof of the PT. Using the applet like a PowerPoint presentation, I asked the students not to take notes but to instead listen carefully as we walked through the argument. Once everyone was convinced, I raised the screen and asked them to help me write it down at the board. This is actually a rather difficult task since the proof has several steps, and our prose could not be shortened by referring to numbered propositions but instead had to include reminders of what facts we were applying. Afterwards, I asked the class to examine what we wrote and discuss the following questions in groups:
There is a marvelous java applet by Jim Morey which animates Euclid’s proof of the PT. Using the applet like a PowerPoint presentation, I asked the students not to take notes but to instead listen carefully as we walked through the argument. Once everyone was convinced, I raised the screen and asked them to help me write it down at the board. This is actually a rather difficult task since the proof has several steps, and our prose could not be shortened by referring to numbered propositions but instead had to include reminders of what facts we were applying. Afterwards, I asked the class to examine what we wrote and discuss the following questions in groups:
- Does this argument convince you that the PT is true?
- What terminology is used in the proof?
- What facts are being applied?
- Most importantly: where exactly is the assumption that the triangle is right used in the argument?
If you watch Morey’s applet, you may miss the answer to 4. It’s actually rather subtle. This brought out some good discussion and I took the opportunity to highlight how a proof can be correct without necessarily being completely clear, and that good proof writing makes the use of assumptions apparent.
After this, I had them engage in a group discussion activity analyzing several different proofs of the PT culled from the list hosted at cut-the-knot.org compiled by Alexander Bogomolny. In addition to my favorite dissection proof of the PT, a similar triangles argument, and Da Vinci’s quadrilateral argument for the PT, I slipped in a false proof to make sure that they were answering question 1 honestly.
The false argument appeared in the American Mathematical Monthly in 1896 and was later retracted. It commits the fallacy of Affirming the Consequent, a mistake that I have seen many students make when first learning proof-writing. This gave a nice segue into the discussion of logic. The seminal achievement of Euclid and the Greek geometers was to take geometric thinking and recast it as a deductive science, in which the known geometric results of the time were organized to follow from a few simple assumptions. This was the birth of the axiomatic method.
I wanted to convey in some manner what an achievement this was. The directed graph below is what I made to do this. The numbers of the nodes correspond to the propositions in Book I of the Elements. Proposition 47 in Book I is the Pythagorean Theorem and is the node at the top. The only propositions in Book I which follow solely from the axioms are Prop. 1 and Prop 4. These are at the bottom. The diagram shows the intervening propositions and their network of implications (there is an arrow from i to j if prop i is used in the proof of prop j), leading from 1 and 4 to the PT at 47.

One could imagine trying to find an axiomatization of geometry by starting with something complicated like the PT, finding a proof of it using certain assumptions, then proving those using simpler ones, and so on until you reach simple candidate statements for axioms. But the fact that Euclid did so in the face of such complexity of implication (perhaps not so complex by modern standards but certainly complex for 300 BCE) is really impressive to me.

 reference points in 3-space stored in a
reference points in 3-space stored in a  matrix and its transformations such as rotation, translation, and scaling implemented by matrix operations.
matrix and its transformations such as rotation, translation, and scaling implemented by matrix operations. in that student’s row and under the project that was their
in that student’s row and under the project that was their  choice. Since their were 30-31 students in each class and only eight projects, I replicated and inserted each column four times to make the matrix nearly square. Then I applied the
choice. Since their were 30-31 students in each class and only eight projects, I replicated and inserted each column four times to make the matrix nearly square. Then I applied the 
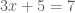 ,” is equivalent to the statement “
,” is equivalent to the statement “ ,” which is equivalent to the statement “
,” which is equivalent to the statement “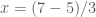 . Since the right hand side of this last equation is equivalent to the fraction
. Since the right hand side of this last equation is equivalent to the fraction  , this last statement informs us of the value of
, this last statement informs us of the value of  is an eigenvalue of an
is an eigenvalue of an  matrix
matrix  ,” is equivalent to
,” is equivalent to ,” is equivalent to
,” is equivalent to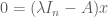 has a nontrivial solution,” is equivalent to
has a nontrivial solution,” is equivalent to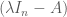 is not invertible,” is equivalent to
is not invertible,” is equivalent to ,” is equivalent to
,” is equivalent to has exactly one solution.
has exactly one solution.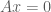 has only the trivial solution.
has only the trivial solution. .
.
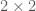 matrix and then defined determinants of higher order square matrices inductively, using cofactor expansion about the first row.
matrix and then defined determinants of higher order square matrices inductively, using cofactor expansion about the first row.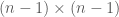 submatrices, you can quickly explain why it takes more than
submatrices, you can quickly explain why it takes more than 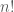 floating point operations in general to compute a determinant. One thing you should get from a course on sequences and series is that the factorial function grows VERY quickly. Faster than the exponential function in fact (just in case my students forgot how fast the exponential function grows, I like to share this
floating point operations in general to compute a determinant. One thing you should get from a course on sequences and series is that the factorial function grows VERY quickly. Faster than the exponential function in fact (just in case my students forgot how fast the exponential function grows, I like to share this  matrix by the definition requires more than a billion billion computations. To put this in perspective, the current MacBook Pros have 2.5 GHz processors, that roughly means 2.5 billion floating point operations per second. In other words, computation of a
matrix by the definition requires more than a billion billion computations. To put this in perspective, the current MacBook Pros have 2.5 GHz processors, that roughly means 2.5 billion floating point operations per second. In other words, computation of a 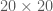 case!
case!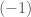 to the number of sign changes does the trick in far fewer steps. This is the way many calculators and other machines are programmed to compute determinants of matrices.
to the number of sign changes does the trick in far fewer steps. This is the way many calculators and other machines are programmed to compute determinants of matrices.

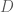 (called the degree matrix), and we work with the difference matrix
(called the degree matrix), and we work with the difference matrix 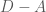 . The (simply amazing) Matrix-Tree Theorem says the following which we can verify in this example.
. The (simply amazing) Matrix-Tree Theorem says the following which we can verify in this example.


 ,
,
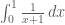 can be calculated using well practiced techniques faster than they can be manually entered and evaluated by computer.
can be calculated using well practiced techniques faster than they can be manually entered and evaluated by computer.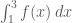 is the symbols
is the symbols  ?
?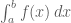 is meaningless/worthless unless you can find a formula for a
is meaningless/worthless unless you can find a formula for a  so that you can write down
so that you can write down 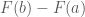 .
. from the great fuel tank problem) can not be calculated using well practiced techniques faster than they can be manually entered and evaluated by a computer.
from the great fuel tank problem) can not be calculated using well practiced techniques faster than they can be manually entered and evaluated by a computer.
 has the right properties to guarantee that
has the right properties to guarantee that  makes sense and gives a number, then it has the right properties to ensure that
makes sense and gives a number, then it has the right properties to ensure that 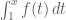 makes sense for each real number
makes sense for each real number  and so one can define a new function
and so one can define a new function 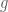 from
from  whenever
whenever ![[1,5]](https://s0.wp.com/latex.php?latex=%5B1%2C5%5D&bg=ffffff&fg=4e4e4e&s=0&c=20201002) , then
, then  , so it should instead be called “techniques for computing formulas for antiderivatives in terms of elementary functions.” Unfortunately, that will never stick. It takes too long to say. But this naming problem leads us to say ridiculous things like, “The integral
, so it should instead be called “techniques for computing formulas for antiderivatives in terms of elementary functions.” Unfortunately, that will never stick. It takes too long to say. But this naming problem leads us to say ridiculous things like, “The integral 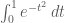 can’t be done,” or “can’t be done exactly.” How confusing is that? It is a mathematical theorem (due to Liouville, I think) that you cannot express the antiderivative of
can’t be done,” or “can’t be done exactly.” How confusing is that? It is a mathematical theorem (due to Liouville, I think) that you cannot express the antiderivative of  in terms of other elementary functions. That means that you can’t express the value of this integral in terms of special values of elementary functions.
in terms of other elementary functions. That means that you can’t express the value of this integral in terms of special values of elementary functions.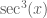 in terms of the other elementary functions when you can use an internet connected computer, or web-enabled mobile device, to instantly answer such a question in an order of magnitude less time than you could doing it by hand? For example, one can type “integrate (sec(x))^3 with respect to x” into
in terms of the other elementary functions when you can use an internet connected computer, or web-enabled mobile device, to instantly answer such a question in an order of magnitude less time than you could doing it by hand? For example, one can type “integrate (sec(x))^3 with respect to x” into 